The Gatekeeper permission engine
The four-value permission model, the deny-confirm-allow-default precedence resolver, non-elevatable operations, and the nuclear-sandbox lockout.
 DollhouseMCP
Open-source AI customization through modular elements
DollhouseMCP
Open-source AI customization through modular elements
Security
DollhouseMCP makes AI behavior programmable, and programmable behavior is an attack surface. This document describes how the platform defends that surface: the architecture, each layer, and the source code that enforces it.
The model rests on one decision: an LLM's instructions are suggestions; the server's policies are the enforcement. Every privileged operation is checked server-side after the MCP client approves the tool call. A permissive client setting cannot bypass the check, and the model cannot reason past it. The boundary is the policy itself, and that policy runs in code the model cannot edit.
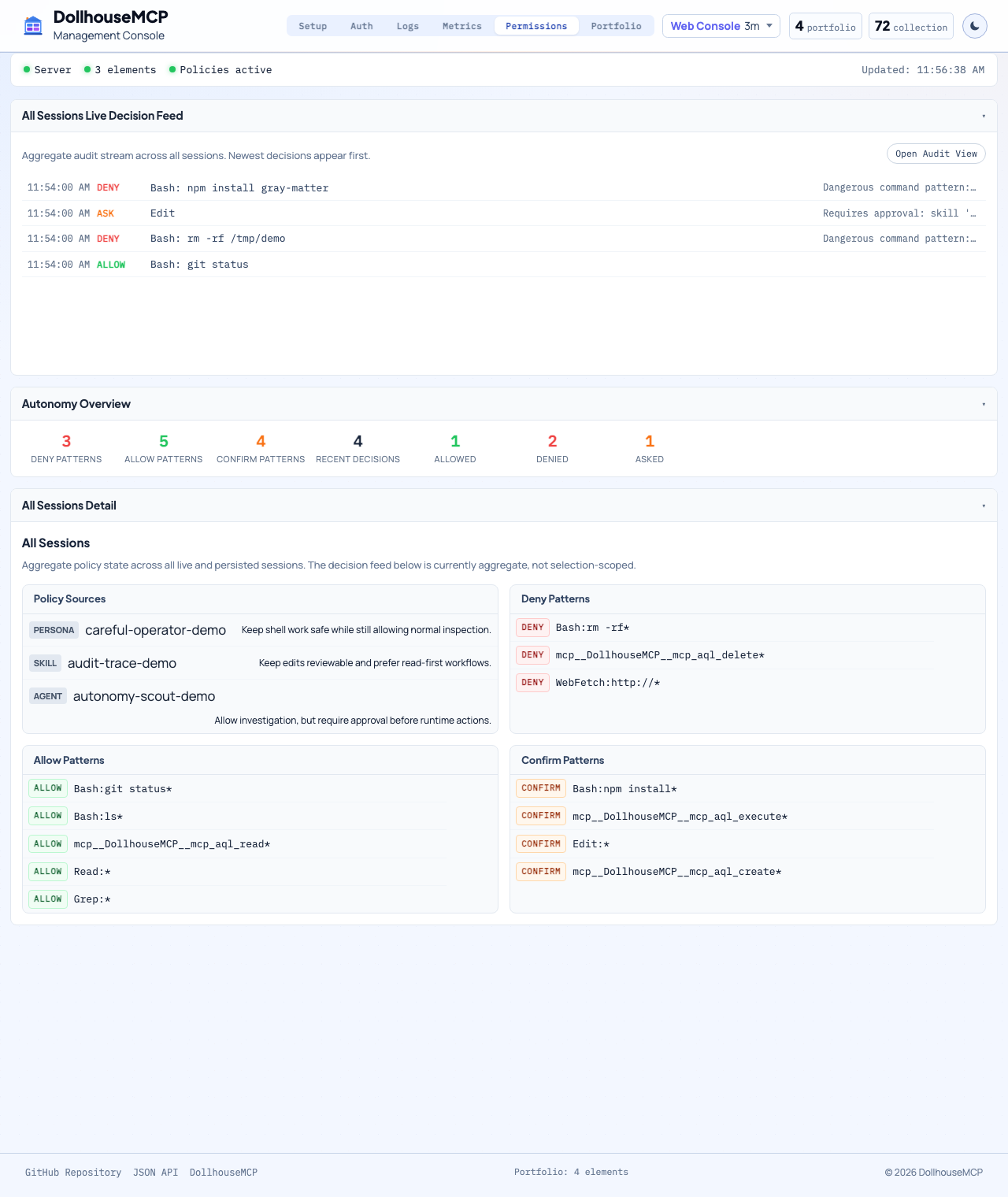
The layers form a path, not a list. Content is sanitized before a request can form, the Gatekeeper decides whether the operation runs, shell-touching commands are risk-scored in transit, and when the caller is an autonomous agent the loop is gated before the next step. The diagram below traces the causal flow end to end.
flowchart TD
LOAD[Element loaded or installed] --> CV[Content validation: injection, Unicode, YAML, ReDoS]
CV -- "rejected" --> STOP[Never reaches the model]
CV -- "clean" --> OP[Model requests an MCP-AQL operation]
OP --> CLI{Shell-touching command?}
CLI -- yes --> TC[CLI tool classification: risk score + irreversible flag]
CLI -- no --> GK
TC --> GK["Gatekeeper: deny then confirm then allow then default"]
GK -- "deny" --> REJ[Operation rejected]
GK -- "confirm" --> HC[Out-of-band human challenge]
HC -- "denied" --> REJ
HC -- "approved" --> EX
GK -- "allow" --> EX[Operation executes]
EX --> FS[Filesystem: path + symlink + atomic write]
EX --> AGENT{Autonomous agent?}
AGENT -- no --> DONE[Done]
AGENT -- yes --> AE[Autonomy evaluator: continue / pause / escalate]
AE -- "continue" --> OP
AE -- "pause" --> HUMAN[Return to human]
AE -- "danger zone" --> DZ[Danger zone enforcer: persistent block]
EX -.-> MON[Security monitor records every decision]
classDef deny fill:#b91c1c,stroke:#7f1d1d,color:#fff;
classDef allow fill:#15803d,stroke:#14532d,color:#fff;
class STOP,REJ,DZ deny;
class EX,DONE allow;
Each layer has a dedicated page covering its enforcement code, with the causal diagram above broken down per layer. The table further down links directly to the source files in the public mcp-server repository.
The four-value permission model, the deny-confirm-allow-default precedence resolver, non-elevatable operations, and the nuclear-sandbox lockout.
The five-stage autonomy evaluator, the file-backed danger zone enforcer, and the out-of-band challenge a compromised model cannot read.
Deterministic prompt-injection detection, Unicode normalization, hardened YAML parsing, and ReDoS protection on every element.
Symlink-aware path-traversal prevention, atomic locked writes, and a strict command allowlist with a stripped environment.
AES-256-GCM token encryption with PBKDF2, constant-time comparison, Unicode-safe strict format checks, and rate limiting.
Validated session identifiers, per-session versioned files, a type allowlist, identifier normalization, and a fail-safe loader.
Tiered command risk scoring, a separate irreversibility flag, additive risk factors, and allowlist-to-denylist policy translation.
These are the enforcing files on the default branch of the public repository, not pseudocode.
| Layer | Enforcing source |
|---|---|
| Gatekeeper permission engine |
GatekeeperTypes.ts,
ElementPolicies.ts,
OperationPolicies.ts
|
| Danger zone enforcement | DangerZoneEnforcer.ts |
| Autonomy evaluator | autonomyEvaluator.ts |
| Content validation |
contentValidator.ts,
unicodeValidator.ts,
secureYamlParser.ts,
dosProtection.ts
|
| Filesystem and process |
pathValidator.ts,
fileLockManager.ts,
commandValidator.ts
|
| Credentials and API |
tokenManager.ts,
consoleToken.ts,
authMiddleware.ts
|
| Activation store isolation | ActivationStore.ts |
| CLI tool classification |
ToolClassification.ts,
AgentToolPolicyTranslator.ts
|
A server that can read files, run commands, call agents, and install community content is both useful and dangerous. The threats are concrete: a persona file can carry a hidden prompt injection, a community element can attempt path traversal, a Unicode homograph can disguise a payload as ordinary text, and a model diverted from its instructions can issue a destructive command. DollhouseMCP assumes every one of these occurs, and is built so that a model that is wrong, compromised, or manipulated is never sufficient on its own to cause harm.
Security is not a single check. It is a stack of independent layers, each defending a different class of threat and each able to stop an operation on its own.
A server-side permission engine that every MCP-AQL operation passes through. Active elements contribute allow, confirm, and deny policies, and the most restrictive rule wins.
Programmatic blocking that survives restarts. An agent that crosses a danger threshold is blocked at the process level until it is verified out of band.
A multi-stage check that gates every autonomous step, returning continue, pause for approval, or escalate, based on risk and reversibility.
Prompt-injection detection, Unicode normalization, safe YAML parsing, and regex-DoS protection, applied to every piece of element content.
Path-traversal prevention with symlink resolution, an extension allowlist, atomic locked writes, and a strict command allowlist for shell execution.
Encrypted token storage, constant-time token comparison, optional TOTP multi-factor, and token-bucket rate limiting on external calls.
Per-session state with validated session identifiers, a type allowlist, and integrity checks, so one session cannot leak into or tamper with another.
Static and pattern-based risk scoring for shell commands, with a separate irreversibility flag, so dangerous and unrecoverable operations are handled differently.
Every MCP-AQL operation passes through the Gatekeeper before it runs. It resolves a permission level from a strict hierarchy — an explicit deny wins over a required confirmation, which wins over an allow, which wins over the endpoint's route default.
deny > confirm > allow > route defaultReads are auto-approved, creation needs a once-per-session confirmation, and update, delete, and execute need a confirmation every time. The most destructive operations are marked non-elevatable, so no element policy can auto-approve them. If an element's deny list includes the confirmation operation itself, the session drops to read-only: denying the mechanism that grants exceptions leaves no path to grant one. Full detail is on the Gatekeeper page.
Some conditions are past the point where a confirmation prompt is sufficient, so the danger zone enforcer applies a
programmatic block instead. An agent that crosses a danger threshold is recorded to disk and stopped, and the block
survives a crash or restart. Clearing it requires an out-of-band challenge: a one-time code shown through an
OS-native dialog and never returned in the model's response, so a compromised model cannot retrieve it. Source:
DangerZoneEnforcer.ts.
Higher agency stays bounded and observable. Before every autonomous step, the autonomy evaluator runs an ordered
set of checks: step-count limits, the outcome of the previous step, action-pattern matching against per-agent
approve and require-approval lists, a safety-tier escalation ladder, and a numeric risk score against a
configurable tolerance. Any one of them can stop the agent. The result is always continue, pause for a human, or
escalate. Source:
autonomyEvaluator.ts.
autonomy:
riskTolerance: conservative # conservative | moderate | aggressive
maxAutonomousSteps: 10
requiresApproval: ["*delete*", "*production*"]
autoApprove: ["read*", "list*"]
Element content is untrusted input. It runs a sequence of checks before any of it can influence the model. Source:
contentValidator.ts,
unicodeValidator.ts,
secureYamlParser.ts,
dosProtection.ts.
Deterministic pattern matching, not an AI classifier that could itself be social-engineered, covering system-prompt overrides, role impersonation, instruction overrides, embedded code execution, and known jailbreak phrasings. Skills can legitimately contain code patterns that would be blocked in a persona, so the check is context-aware.
Detection and normalization for direction-override characters, zero-width injection, mixed-script homograph spoofing, and non-printable control codes, with NFC normalization applied at the validation boundary.
A safe schema only, with size limits and YAML-bomb detection, so circular references, anchor-to-alias amplification, and oversized documents are rejected before they can detonate.
Pattern execution runs under timeouts with complexity classification, so a crafted input cannot trigger catastrophic backtracking and hang the server.
Field-specific validation for identifiers, queries, paths, and URLs, including blocking the IP-address formats that enable server-side request forgery. Every string value is normalized before downstream validation.
Content shipped inside the npm package is registered by SHA-256 hash, so trusted bundled elements are not re-scanned against injection patterns they would falsely trip. A hash mismatch after install revokes that trust immediately.
Source:
pathValidator.ts,
fileLockManager.ts,
commandValidator.ts.
Every path is resolved to its real file, symlinks included, before it is checked against the allowed portfolio directories and an extension allowlist. There is no ../.. escape and no symlink redirect out of the sandbox.
Per-file locking with timeouts serializes concurrent writes, and a write-temp-then-rename pattern means a crash cannot leave a half-written portfolio file.
Shell execution is restricted to a small allowlist with no shell metacharacters, a restricted PATH, per-argument validation, and a default timeout.
Source:
tokenManager.ts,
consoleToken.ts,
authMiddleware.ts.
The GitHub token is validated by format, encrypted at rest with AES-256-GCM under a PBKDF2-derived key, and redacted from every log line and error message.
Console auth is enforced only when DOLLHOUSE_WEB_AUTH_ENABLED is set; during the current Phase 1 rollout it is off by default and the middleware is a deliberate no-op. When enabled, the console uses a crypto-random bearer token — stored in an owner-only file rather than encrypted — compared in constant time, Unicode-normalized and strict-hex-checked before the comparison to close a normalization-bypass class.
The console supports RFC 6238 time-based one-time passwords with backup codes, for a second factor on local administrative access.
Token-bucket rate limiting with exponential backoff governs GitHub API traffic, verification attempts are limited on a sliding window, and downloads enforce timeouts, size limits, and protocol allowlisting.
Active-element state is persisted per session. Session identifiers are regex-validated to prevent path injection,
each session writes a separate versioned activation file, only known element types are accepted, identifiers are
normalized, and a corrupt or missing file starts fresh with a logged security event rather than failing open. An
ephemeral mode disables persistence entirely. Source:
ActivationStore.ts.
When elements drive external CLI tools, every command is classified before it runs. A static map and a large pattern set sort commands into safe, moderate, dangerous, and always-blocked tiers, and assign a 0–100 risk score weighted by irreversibility, network access, out-of-scope paths, and sensitive locations.
Risk and reversibility are tracked separately by design. git checkout -b feature scores as risky but
is trivially undone, while git stash drop appears routine but is irrecoverable, so a dedicated
irreversibility flag gates unrecoverable operations even when their raw score is modest. Elements can constrain
tools further with explicit allow, confirm, and deny patterns and an approval policy that carries its own scope and
TTL. Source:
ToolClassification.ts,
AgentToolPolicyTranslator.ts.
externalRestrictions:
allowPatterns: ["Read:*", "Glob:*", "Bash:git status*"]
confirmPatterns: ["Edit:*", "Write:*", "Bash:git push*"]
denyPatterns: ["Bash:rm *", "Bash:sudo *"]Community-contributed content is untrusted until it has been validated. Every user-contributed element runs the full content-validation pipeline before it is trusted, external resources are validated on install, duplicate detection warns before redundant publishing, and GitHub uploads are validated before any community issue is created. The Collection is a shared library, not an implicitly trusted one.
The defenses are verified on an ongoing basis, not only at release.
CodeQL runs on every push and pull request and on a daily schedule across the JavaScript and TypeScript codebase.
A rule-based security auditor runs on every push and pull request and daily, reporting to SARIF, commenting on pull requests, and opening issues for critical findings.
Pull requests are blocked on moderate-or-higher runtime dependency vulnerabilities.
A weekly job reconciles the dependency tree against the OSV and GitHub advisory databases, catching withdrawn advisories, new fixes, and severity reclassifications.
A standing suite of security-specific tests covers input validation, path traversal, command injection, YAML deserialization, token handling, memory injection, Unicode attacks, ReDoS, and OWASP Top 10 categories, and runs both on its own and in pre-merge checks.
Security reports go through GitHub private security advisories. The project commits to triage timelines by severity, publishes fixes with coordinated GHSA advisories, and provides critical fixes for the most recent supported minor versions. The full policy is in SECURITY.md in the public repository.
DollhouseMCP makes AI behavior programmable and gates that power at every step. The model can be wrong, the content can be hostile, and the client can be too permissive; none of these is sufficient on its own, because the enforcement does not live in the prompt. It lives in the server.